




Le Big Data, ou mégadonnées en français, est un concept qui désigne un ensemble très volumineux de données qu’aucun outil de gestion de base de données conventionnel ne peut traiter.
Voilà pour la définition simpliste. Mais non seulement le Big Data, c’est bien plus complexe que ça, mais on ne sait pas toujours à quoi il sert réellement. Or, Le Big Data peut être utilisé de façons bien différentes.
Dans cet article, nous verrons ce qui caractérise réellement le Big Data, quels en sont les usages et ce qu’il implique au niveau technologique.
Big Data : définition
Rentrons un peu plus dans les détails. On l’a dit, le Big Data, c’est un concept représentant un très gros volume de données.
Derrière ce concept se cachent de nombreuses choses : beaucoup d’applications diverses (marketing, médical, environnemental, politique, etc. – on en reparlera) ; mais aussi de nouveaux besoins technologiques.
Pour avoir une définition plus complète du Big Data, on peut commencer par évoquer les 6 ‘V’ qui définissent le Big Data.
Les 6 ‘V’ du Big Data
À l’origine, on n’avait que 3 de ces ‘V’ : le volume, la variété et la vélocité. Encore aujourd’hui largement utilisé, ce modèle a été enrichi de trois nouveaux éléments : la véracité, la valeur, et la visualisation.
1) Volume
Évidemment, les mégadonnées sont définies par leur volume. Comme on l’a dit, le Big Data, c’est une masse de données qui ne peut être traitée par un système conventionnel ; donc un volume très important.
Et dans le cadre du Big Data, on parle de volumes très conséquents.
Pour parler volume brut, les données qui sont créées quotidiennement sont massives. Par exemple, le radiotélescope “Square Kilometre Array” produit 7 000 téraoctets de données par seconde. Elles ne sont évidemment pas stockées et traitées telles quelles, mais c’est un exemple révélateur.
2) Variété
Le Big Data est aussi défini par sa variété. C’est à dire que les sources de données peuvent être extrêmement variées (que ça soit par leur origine ou leur format informatique) et d’autant plus difficiles à agréger et à interpréter.
C’est là qu’interviennent les spécialistes des data sciences, tels que le data scientists.
3) Vélocité
La vélocité, c’est la fréquence à laquelle les données sont produites et ajoutées aux données déjà existantes. Mais c’est aussi une problématique de vitesse d’analyse. Dans certains domaines (par exemple en bourse), une analyse en quasi temps-réel est nécessaire, ce qui pose de réelles difficultés techniques.
4) Véracité
La véracité des données, c’est la fiabilité de ces données. Il faut en effet prendre en compte la qualité des données stockées et analysées dans la lecture qu’on va en faire.
5) Valeur
Le Big Data est aussi caractérisé par la valeur qu’il ajoute, une fois traité. Se mettre à analyser du Big Data (dans le but de faire de la business intelligence, par exemple), est coûteux, et doit apporter une certaine valeur ajoutée par la suite.
6) Visualisation
Enfin, il est important, pour que les analyses tirées du Big Data soient utiles, qu’elles aient une forme facilement lisible et compréhensible. On fait notamment appel ici à la Data Visualisation, science qui permet de représenter graphiquement des données massives brutes.
L’exploitation du Big Data

Mais la puissance du Big Data ne réside ni dans le nombre de données, ni dans la variété de ces données. Ce qui compte vraiment, pour une organisation, ce sont les capacités de traitement et la manière dont elle va utiliser ces données collectées.
Et qui dit capacités de traitement dit spécialistes du traitement du Big Data.
Les experts des data sciences
Et pour ça, on fait appel à des experts des data sciences, comme les data engineers ou les data scientists.
Ces métiers, relativement nouveaux, sont exercés par des spécialistes qui, grâce à diverses technologies, rendent utilisables les données du Big Data et créent des programmes en se basant dessus.
Exemples d’exploitation du Big Data
Pour mieux comprendre ce qu’on peut faire avec du Big Data, voyons quelques exemples d’exploitation de mégadonnées.
De la recommandation personnalisée
En analysant tout un panel de données de ses clients ou utilisateurs, un (e-)commerce peut mettre au point des recommandations et promotions personnalisées à chacun. Par exemple, ces promotions pourraient dépendre de :
- La date (jour de la semaine, vacances, férié, etc.) ;
- La météo ;
- L’âge du client ;
- Son adresse ;
- Son heure de visite / d’achat ;
- etc.
Toutes ces données, multipliées par le nombre de clients, forme un ensemble de data, qui peut ensuite être exploité. Par exemple pour recommander le même produit acheté l’an passé par un client l’année suivante, lorsque les mêmes conditions sont réunies.
C’est ce qu’on appelle le commerce prédictif. Et ce n’est pas nouveau, Target, la chaîne de magasins américaine, utilise ces techniques depuis des années déjà. Elles sont même tellement au point qu’en analysant les masses de données collectées, la firme arrive à détecter qu’une femme est enceinte… sans qu’elle ne l’ait dit à personne. Plus d’informations sur cette histoire ici.
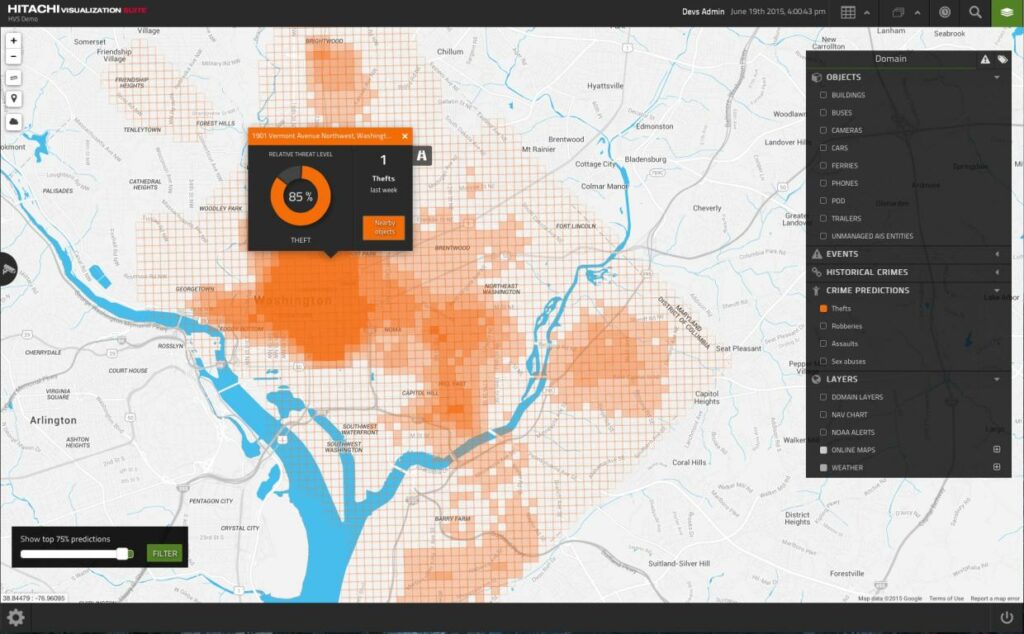
L’analyse prédictive de criminalité
Un autre cas concret qu’on pourrait citer ici, c’est celle de l’entreprise japonaise Hitachi, qui a mis au point un programme censé prédire la criminalité dans une ville. Pour cela, elle analyse une quantité importante de données, telles qu’entre autres :
- Les statistiques de la police ;
- les conversations échangées sur les réseaux sociaux ;
- La météo.
Pour ensuite générer une heat map des risques de crimes dans une région définie.
Bien sûr, ce ne sont que deux exemples, mais il y a des utilisations de la Big Data qui ont une action bien plus concrète. On peut parler par exemple de détection de maladies à partir de radios, via un programme entrainé grâce à de millions de diagnostics (et basé sur le machine learning).
Mais aussi, le Big Data peut intervenir dans la recherche scientifique, l’écologie, et également dans la politique.
Les limites d’utilisation du Big Data
Si le Big Data et l’analyse qui en est faite peut être un outil très puissant, il a toutefois des limites, techniques ou éthiques.
Techniquement parlant, le Big Data pose deux principaux problèmes :
- L’analyse en temps réel – ou presque – d’une grosse quantité de données n’est pas facile ;
- Le stockage de milliards de milliards de données est un véritable challenge, comme nous allons le voir.
Ensuite, éthiquement et légalement, les mégaonnées ont aussi leurs limites :
- Le respect de réglementation, comme le RGPD ;
- La transparence sur les données collectées et traitées ;
- L’utilisation dérivée qui peut être fait par le Big Data – dans l’objectif d’influencer des comportements (achats) ou de manipuler des opinions.
Le Big Data dans la technologie
Les technologies de stockage
Le Big Data est donc une immense quantité de données, et comme on l’a dit, la stocker est un véritable défi.
Quand on parle d’immense quantité de données, c’est peu dire. Prenons un autre exemple. Le Large Hadron Collider du CERN possède environ 150 millions de capteurs délivrant des données 40 millions de fois par seconde. Avec 600 millions de collisions chaque seconde, et même après filtrage, il reste 25 Po (pétaoctets, soit 25 000 téraoctets) de données à stocker par an.
Même si les technologies de stockage sont aujourd’hui moins coûteuses que par le passé, stocker autant de données a évidemment un coût.
On se tournera alors vers des données de stockage sur le cloud, comme Amazon Simple Storage Service (S3).
Les technologies d’analyse
Concernant les outils d’analyse du Big Data, et sans trop rentrer dans les détails trop techniques, nous allons ici parler de Hadoop, MapReduce et Spark.
Hadoop
Hadoop est un framework open source développé par Apache conçu pour l’exploitation du Big Data.
Cette solution logicielle fractionne les données en blocs, puis les distribue à travers des nœuds. Pour traiter ces données, Hadoop transfère le code à chaque nœud, qui traite alors la data dont il dispose.
Hadoop fonctionne autour de quatre modules :
- Hadoop Common ;
- Un système de gestion de fichiers : Hadoop Distributed File System ;
- Hadoop YARN ;
- Hadoop MapReduce – son implémentation de MapReduce.
MapReduce
MapReduce n’est pas un outil à proprement parler, mais plutôt un pattern, un patron d’architecture.
Inventé par Google, il permet d’effectuer efficacement des calculs parallèles et distribués sur des données volumineuses.
Son nom, emprunté à des concepts de programmation fonctionnelle (map et reduce) décrit parfaitement ce qu’il fait :
- Dans l’étape map, on analyse le problème (les données), le découpe en sous-problèmes et l’envoie vers des noeuds, qui peuvent en faire de même ;
- Lors du reduce, les noeuds les plus bas font remonter leurs résultats aux noeuds parents qui les avait sollicités.
Spark
Spark, appartenant comme Hadoop à la fondation Apache, en est pourtant quelque peu le concurrent.
Plus récent qu’Hadoop, il doit son succès à sa vitesse de traitement des données ; il est en effet 10 à 100 fois plus rapide que son prédécesseur. La raison de cette différence est que Spark garde les résultats de ses opérations d’analyse en mémoire pendant leur exécution. De l’autre côté, Hadoop écrit les données sur des disques après chaque opération.
L’inconvénient, c’est que contrairement à Hadoop et son HDFS, Spark n’intègre pas de système de gestion de fichiers. Il faudra alors lui en fournir un.
Conclusion
On l’a vu, le Big Data est quelque chose de complexe avec un gros enjeu stratégique, tant au niveau sociétal que pour une entreprise.
Bien que le Big Data impose des limites (notamment éthiques), son utilisation est importante, et va continuer à le devenir au fur et à mesure que nous produisons (et stockons) des données par milliards.
Le Big Data et les métiers de la data science ont un bel avenir devant eux !

